AG官方最新版app下载 名师一定出高徒? 清华团队最新揭秘: 别再迷信大模子蒸馏免费午餐


本文由清华大学 THUNLP 实验室颐养上海科技大学、伊利诺伊大学厄巴纳-香槟分校、中国东说念主民大学等多家机构商议者妥洽完成。
蒸馏的免费午餐,简直好意思味吗?
当下的大模子后历练(Post-training)pipeline 中,On-Policy Distillation(OPD)仍是成为了明星本领。从 Qwen3、MiMo 到 GLM-5,业界纷繁汲取 OPD 并论述了雄伟的性能擢升。比较于强化学习(RL)稀少的收尾奖励,OPD 提供了密集的 Token 级别监督信号,看起来就像是一顿「免费的午餐」。
但如若你亲手跑过 OPD,你可能会遭逢一个反直观样式:为什么我换了一个更强的 Teacher,Student 的性能反而毫无擢升,以致出现了倒退?
大模子时间的蒸馏,早就不是肤浅的「浪漫出古迹」了。
清华大学团队最新的一项商议,系统性地剖解了 On-Policy 蒸馏的黑箱。这篇论文不仅揭示了决定蒸馏成败的两大先决条目,还深挖了 Token 级别的对都机制,并给出了接济失败蒸馏的实用配方。
论文蚁集:https://arxiv.org/abs/2604.13016
代码库:https://github.com/thunlp/OPD
Thread https://x.com/HBX_hbx/status/2044464414829777354
样式篇:为什么「名师」出不了「高徒」?
银河国际游戏平台官网在成例闪现中,Teacher 模子的分数越高,蒸馏效力应该越好。但商议团队通过严谨的对比实验,发现了按捺 OPD 庆幸的两个中枢律例:
律例一:念念维模式一致性(Thinking-Pattern Consistency)
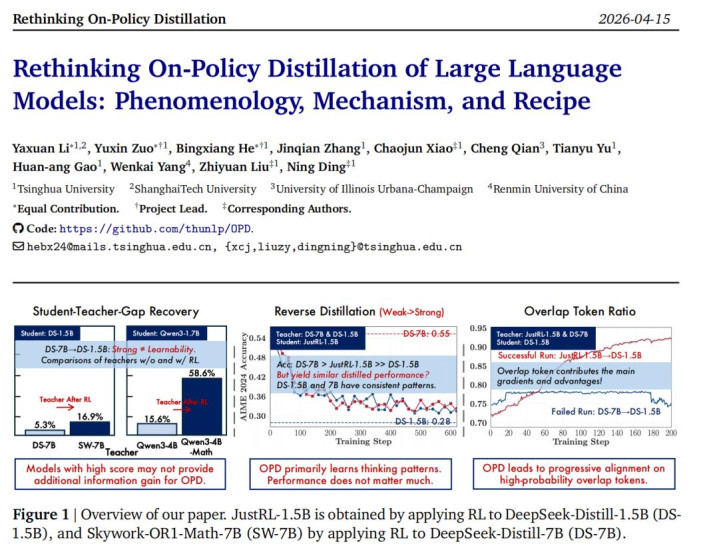
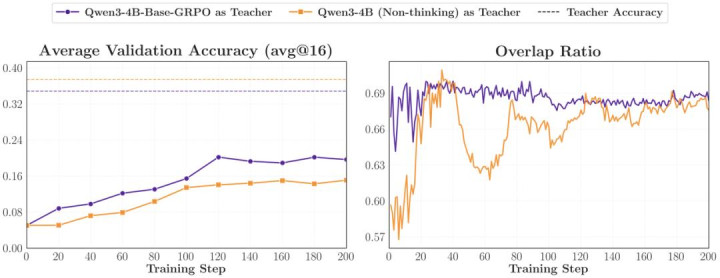
商议者让弱 Base 模子 Qwen3-1.7B-Base 向两个智力周边的 Teacher 学习:一个是 Qwen3-4B (Non-thinking) ,另一个是只经过 GRPO 历练的 Qwen3-4B-Base-GRPO。收尾发现,由于学生亦然 Base 模子,它与经过 GRPO 强化的 Base Teacher 的 thinking pattern 更近(运转 Overlap Ratio 更高),最终的蒸馏效力获取了显贵擢升。如若早期念念维模式错配,后续很难十足弥补。
律例二:高分 ≠ 新常识(Higher scores ≠ new knowledge)
如若竭诚和学生念念维模式一致,且竭诚分数更高,蒸馏就一定管用吗?
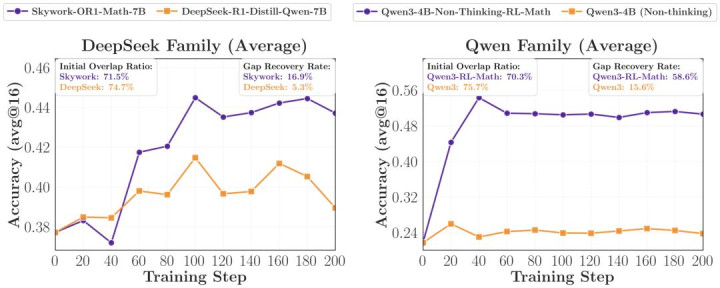
商议者在 DeepSeek 和 Qwen 两个 family 里都看到相通的样式:同 pipeline、同 recipe、仅仅更大少量的 teacher,擢升颠倒有限;反而是经过额外 RL post-training 的 teacher,能规复更多 teacher-student gap。比如在 DeepSeek family 里,经过 RL 的 Skywork-OR1-Math-7B gap recovery 是 16.9%,而同 pipeline 的 DeepSeek-R1-Distill-7B 唯一 5.3%;在 Qwen family 里,这个差距以致达到 58.6% 对 15.6%。
这评释如若竭诚仅仅吞并条 pipeline、吞并种数据和 recipe 下作念得更大,它在学生眼里可能仅仅「吞并类分散的不同范例版块」,并不会提供若干新的可迁徙信号。
最狠的实验,是把学生「蒸馏且归」
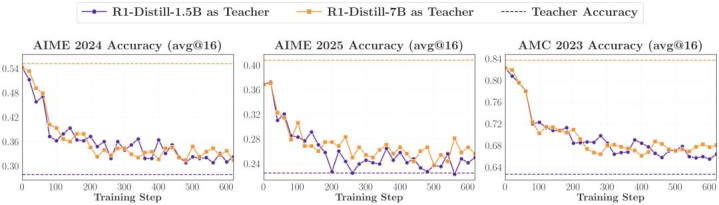
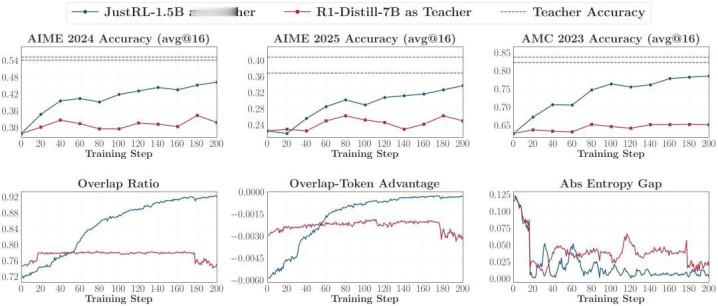
商议者作念了一个号称极点的「反向蒸馏」实验:用 RL 后的 JustRL-1.5B 作念学生,让它反过来向我方 RL 之前的 checkpoint R1-Distill-1.5B 学习;同期再拿一个更大、分数也更高的同眷属 R1-Distill-7B 来作念对照。
收尾很不测:向 7B 学习和向 1.5B 学习,效力险些一样 —— 都让学生的智力倒清偿了前 RL 的水平,而且下落弧线颠倒周边!这评释,7B 固然分数高,但它相较于 1.5B 仅仅参数界限带来的红利,并莫得提供 Student 更多可学习的信息。 OPD 并不是在肤浅地「学习高分」,而是在主动索求并复刻竭诚的念念维模式。
机制篇:Token 级别的显微镜,看到了什么?
当 OPD 成效或失败时,在 Token level 到底发生了什么?
商议者监控了历练全经由的动态认识,发现了一个极为了了的端正:成效的蒸馏,ag官方网站登录入口是一场高概率 Token 的「双向奔赴」。
在成效的 OPD 中,Student 和 Teacher 的前 k 个瞻望 Token 的访佛率(Overlap Ratio)会从 72% 稳步攀升到 91% 以上,同期两者的熵差距(Entropy Gap)飞快疲塌。而在失败的 OPD 中,这些认识从新到尾基本无变化。
更热切的是的发现是:「访佛区域」就是一齐。
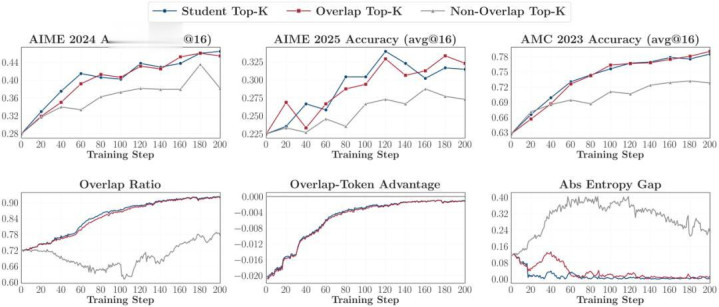
商议者把蒸馏方向隔断,作念了一组剥离实验。他们发现,那些被师生共同看好的高概率 Token 是扫数优化的中枢引擎,孝顺了主要梯度和上风。如若只对这些 Overlap Token 打算亏空,蒸馏性能险些不打扣头!而那些非访佛的 Token 对优化险些毫无孝顺。
处方篇:两招接济「不可救药」的蒸馏
如若手头唯一念念维模式不契合的 teacher,是不是就安坐待毙了?基于上述样式和机制,商议者给出了两剂「振领提纲」的药方:
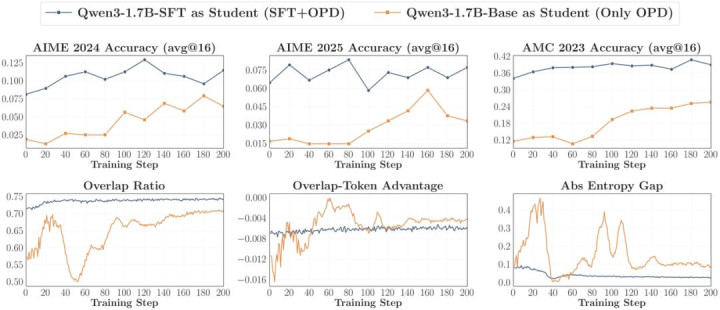
1. 西宾 Rollout 上进行 Off-Policy 冷启动(Cold Start)
既然一上来就径直 On-Policy Distillation 容易发生念念维方式的不匹配,那就先用 Off-Policy 强行对都。在入手 OPD 之前,先让 Student 在 Teacher 生成的 rollout 上进行一轮轻量级的 SFT。这能径直拉高运转的 Overlap Ratio ,在随后的 OPD 历练成能丝滑启动,最终管制的性能上限卓越纯 OPD baseline。
2. 与西宾对都的教唆词(Teacher-aligned Prompts)
既然 teacher 的计谋是在某类 post-training prompt 上被塑造出来的,那就尽量让 OPD 看到更接近 teacher 历练分散的 prompt,包括模板层面的对都和执行层面的对都。论文发现,这如实能进一步擢升 accuracy 和 overlap growth;但代价是 student entropy 会降得更快,是以最佳和一部分 OOD 的 prompt 混用,幸免过早发生熵坍塌。
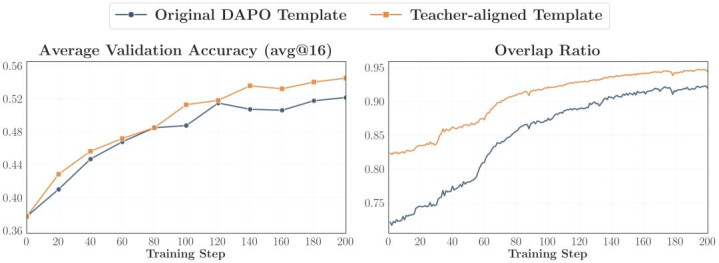
Template 对都
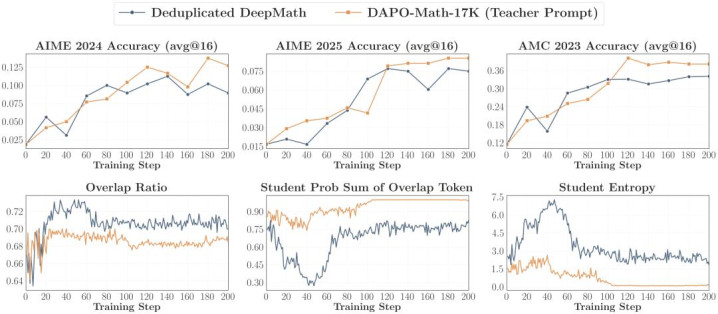
Content 对都
筹商与反念念:OPD 简直能无尽 Scaling 吗?
免费的密集奖励信号如实很诱东说念主,但商议者发现奖励信号的质料会跟着轨迹深度急剧衰减。
在长达 15K token 的反映中,商议者不雅察到了了了的「从后上前的熵垮塌」:跟着生成的久了,Student 的前缀越来越偏离 Teacher 熟练的分散,导致 Teacher 在后半段给出的奖励酿成了隧说念的杂音,进而激勉扫数历练的坍塌。这评释 OPD 当今很难径直彭胀到长念念维链或 agentic 多轮场景。密集监督与监督可靠性之间存在根人道张力。
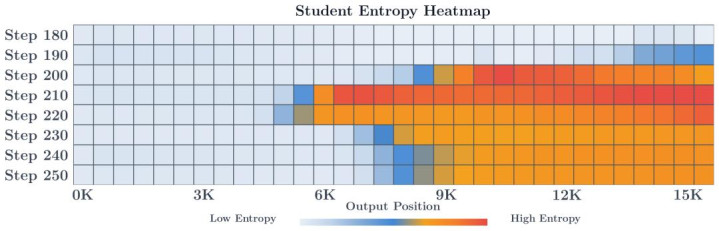
此外,全局有用的奖励,不代表局部能被灵验优化。失败 teacher 给出的全局 reward 其实并不弱,永诀正确 / 诞妄 rollout 的 AUROC 以致和成效 teacher 周边,这评释失败不是因为 reward 信号自己莫得信息量,而是因为 reward 的局部优化几何结构出了问题 —— 全局有信息,局部却平坦。
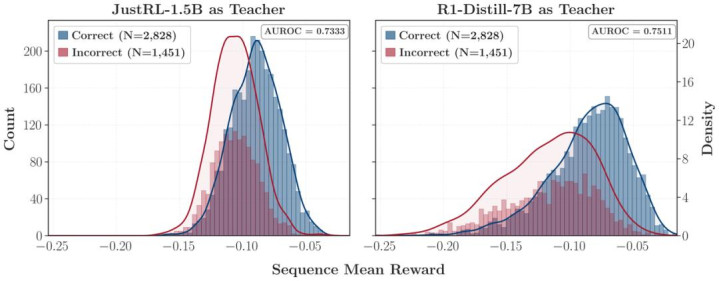
写在临了:对于「更强」与「更可学」
咱们习尚了去寻找一个更大的模子来索修业识,想天然觉得越强的西宾教的越好。但这篇论文给出的谜底是:有时。在 OPD 里,更强不自动等于更会教。高分不自动等于新常识。大模子也不仅仅把智力「灌」给小模子,它更像是在传递一种念念维旅途、一种局部偏好的组织方式。
是以真实的问题,不是「teacher 有多强」,而是:
它和 student 说的是不是吞并种话语?
它带来的东西,是不是 student 还没真实学会的东西?
它给出的监督,能不行在 student 现时所在的位置上,酿成有用的梯度?
而这,也许恰是这篇论文最有价值的场地:它莫得再给 OPD 加多一个新 trick,而是第一次比较系统地告诉咱们 —— 为什么有些 teacher 能熏陶学生AG官方最新版app下载,为什么有些 teacher 仅仅在「看起来更强」。
 备案号:
备案号: